最も簡単・確実だと思われる方法について紹介します.
背景
Word ファイルにおいて,内容を削除する意図で取り消し線を使用することは良くあるかと思います.
例えば次のような感じ.
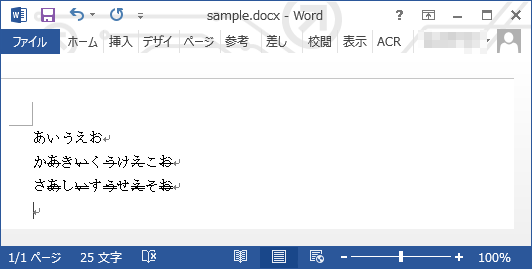
これらの表記は,人間からすると削除するという意図は伝わってくるのですが,ファイルをプログラムで処理する場合にはちょっと厄介です.そこで,それらの表記を踏まえてセルの内容を取得するスクリプトを作ってみました.
スクリプト
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#!/usr/bin/env ruby # -*- coding: utf-8 -*- require 'win32ole' def get_norm_text(text_range) char_list = [] text_range.Characters.each do |char| next if ((char.Font.StrikeThrough != 0) || (char.Font.DoubleStrikeThrough != 0)) char_list.push(char.Text) end return char_list.join("") end begin word = WIN32OLE.new("Word.Application") word.DisplayAlerts = false fso = WIN32OLE.new('Scripting.FileSystemObject') doc = word.Documents.Open({ FileName: fso.GetAbsolutePathName('./sample.docx'), ReadOnly: true }) doc.Paragraphs.each do |para| puts get_norm_text(para.Range).gsub(/\a|\r|\n|\f/, "").strip end ensure word.Quit end |
get_norm_text という関数が取り消し線をハンドリングする部分です.
冒頭に掲載した内容の sample.docx ファイルに対して上記のスクリプトを実行すると,以下の出力が得られます.取り消し線や二重取り消し線が設定された文字が削除されていることが分かるかと思います.
|
1 2 3 |
あいうえお かきくけこ さしすせそ |
解説
処理のポイントは,Characters によって範囲内の文字を一文字づつ取得している部分です.これを使うと,文字毎の書式を取得できるため,簡単に取り消し線が設定された文字を削除することができます.


コメント