
Raspberry Pi でセンシングしたデータをログ収集ツール Fluentd を使って簡単に収集する方法を紹介します.
全体構成
今回想定しているのは下図のような構成です.
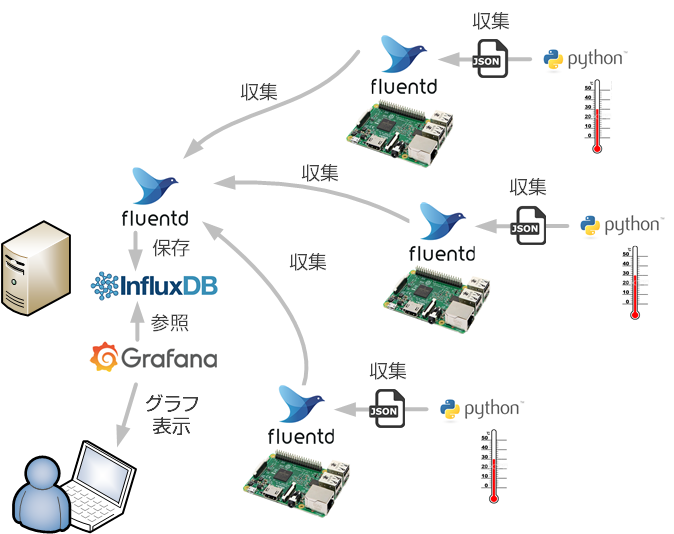
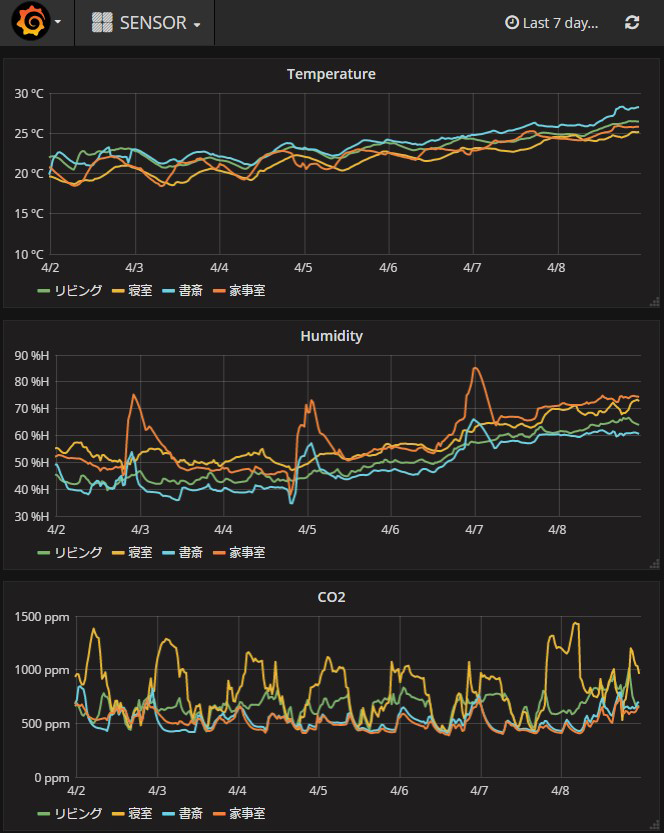
複数の Raspberry Pi でセンシングを行い,測定値を Fluentd を使ってサーバーに集約します.集約したデータは時系列データベース influxDB に格納します.また,格納されたデータはモニタリングツール Grafana で下記のようにグラフ化します.
Fluentd と Raspberry Pi の組み合わせはまだ例が少ないですが,以下の点でおすすめです.
- 厚いユーザー層.サーバサイドのデータ収集基盤として広く使われており,設定例やトラブルシューティングの事例が豊富です.
- 拡張性が高い.綺麗な設計をベースとして様々なプラグインが用意されており,データベースの乗り換えや同時に複数のデータベースに格納するといったことが簡単に行えます.
- 耐障害性が高い.通信が途絶えてもその間に収集したデータが失われないようになっているため,センサーネットワークと相性が良いです.
Raspberry Pi の Fluentd 設定
公式ページに記載されている Debian Jessie の手順に従ってインストールを行います.
その後,下記のような設定ファイルを作成し,起動時にこのファイルを使って Fluentd が自動的に起動するようにします.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
<system> log_level info </system> <source> @type exec tag sensor # データを収集するスクリプトのパス.出力は JSON. command python "/home/pi/rasp-python/app/sense_env/sense_env.py" format json run_interval 10s </source> <filter *.**> @type record_transformer <record> hostname "#{Socket.gethostname}" </record> </filter> <match *.**> @type forward buffer_type memory buffer_chunk_limit 2m buffer_queue_limit 256 retry_limit 100 retry_wait 10s max_retry_wait 2h flush_interval 60s <server> # サーバーのホスト名を指定 host "columbia.green-rabbit.net" </server> </match> |
設定のポイントは下記になります.
command python "/home/pi/rasp-python/app/sense_env/sense_env.py"- センシング結果を JSON で出力するスクリプトを指定します.
私の場合,下記のような JSON を出力するスクリプトを使用しています.
1{"press": 1019, "lux": 6.0, "humi": 54.19, "co2": 788, "temp": 23.8} hostname "#{Socket.gethostname}"- record_transformer でこの項目を設定することで,Raspberry Pi が送信するデータにホスト名を組み込みます.これにより,データがどの Raspberry Pi から送られてきたのか識別できるようになります.Grafana でのグラフ化の際に必要になります.
host "columbia.green-rabbit.net"- データを収集するサーバのホスト名を指定します.
サーバの Fluentd 設定
下記のように設定します.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
<system> log_level info </system> ################################################################################ # フィルタ ################################################################################ <filter sensor.**> type record_transformer auto_typecast enable_ruby <record> temp ${record["temp"].to_f} humi ${record["humi"].to_f} lux ${record["lux"].to_f} </record> </filter> ################################################################################ # 処理 ################################################################################ <match sensor.**> @type copy <store> @type influxdb host localhost # データベースの名前 dbname sensor tag_keys ["hostname"] time_precision s </store> </match> <match debug.**> @type stdout </match> ################################################################################ # ソース ################################################################################ <source> @type forward </source> <source> @type http port 8888 </source> <source> @type debug_agent bind 127.0.0.1 port 24230 </source> |
設定のポイントは下記になります.
dbname sensor- あらかじめ作成しておいた influxDB のデータベース名を指定します.
record_transformer- 測定値が float で出力されるように強制変換しています.
これにより,JSON での値が整数値でも,InfluxDB には浮動小数点として入力されます.これをやっておかないと,InfluxDB は測定値が整数になった場合に「XXX is type int64, already exists as type float」というエラーを吐くようになってしまいます. tag_keys ["hostname"]- Grafana でセンサー毎にグラフ化するため,Raspberry Pi から送られてくる hostname をタグキーに指定します.
サーバの InfluxDB 設定
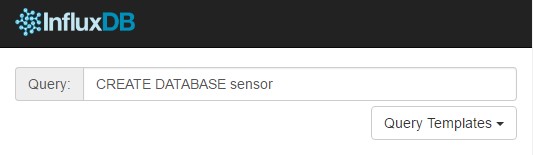
http://サーバーのIPアドレス:8083 にアクセスし,下図のように CREATE DATABASE sensor と入力して ENTER を押します.これにより InfluxDB に sensor という名前のデータベースが作成されます.
サーバの Grafana 設定
http://サーバーのIPアドレス:3000 にアクセスし,ブラウザ上で設定を行っていきます.初回アクセスだと ID とパスワードを求められますので共に admin をしていしてログインします.
まず,下図のようにデータソースの設定を行います.

続いて描画するグラフの設定を行います.ほとんどの設定は見ればやりかたわかると思いますが,データの系列を指定する Metrics はやや込み入っているので解説します.
設定としては下記のようにします.
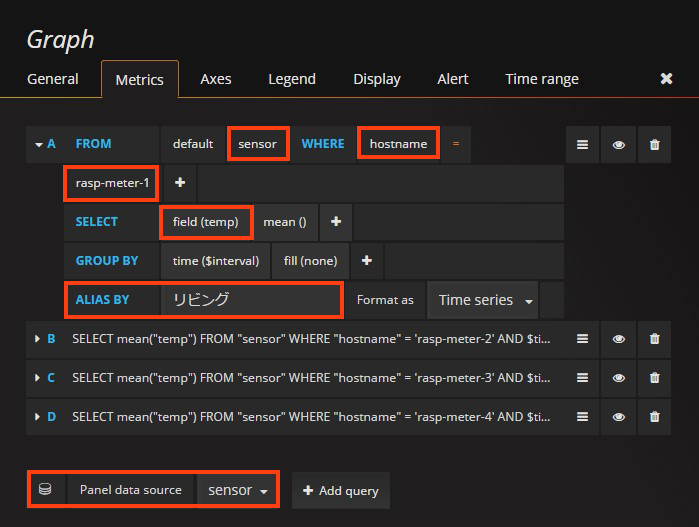
設定の流れは以下の通りです.
- 一番下の「Panel data source」に先ほど作成したデータソースを指定します.
- データソースに含まれるデーターベース名を指定します.設定場所は「FROM」の横の欄です.
- グラフ化したいホスト名を指定します.まず「WHERE」の横の欄をクリックし,InfluxDB でタグキーに設定した「hostname」を指定します.続いて次の入力欄をクリックし,ホスト名を選択します.図の場合「rasp-meter-1」を選択しています.
- グラフ化したいデータを指定します.「SELECT」の横の入力欄をクリックして選択します.図の場合「temp」を選択しています.
- 好みに応じてグラフに表示される系列名を指定します.「ALIAS BY」の横の入力欄に記載します.
あとは,これをグラフ化したい系列毎行えば完成です.
注意点
今回使用している InfluxDB と Grafana の組み合わせとっても手軽にグラフ化できて便利なのですが,1 つだけ大きな欠点があります.それは,特定のデータを削除したり編集したりすることが現時点でできないこと.そのため,各 Raspberry Pi が実行するスクリプトで異常値をはねるようにしておかないと,何かの事情で変なデータが入るとちょっと残念な事になります.
InfluxDB もいろいろと改善が続いているようですので,そのうち何か手が打たれるとは思いますが.(例えば,少し前のバージョンだと整数と浮動小数点の扱いでも落とし穴があったのですが,現在は改善されます.)

コメント
初めまして。電波時計の記事を見つけて、いろいろと楽しく読ませていただきました。
全部を読んだわけではないのですが、ひっそりとCO2の測定がされています。
もしよろしければ、お使いのCO2のセンサーを教えていただけますでしょうか。
センサーは K-30 を使っています.Aliexpress とかだともっと安価なもの
あるようですが精度と信頼性を重視してこちらにしました.
https://www.co2meter.com/products/k-30-co2-sensor-module
早速ありがとうございます。
やはり高級品でしたか。。。
少なくとも4か所測定されているようでしたので。安物買いの、になるよりはですかね。
[…] Fluentd と Raspberry Pi で作るセンサーネットワーク – Rabbit NoteRaspberry Pi でセンシングしたデータをログ収集ツール Fluentd […]