
Collectd を使って ZFS の空き容量をグラフ化する方法を紹介します.
はじめに
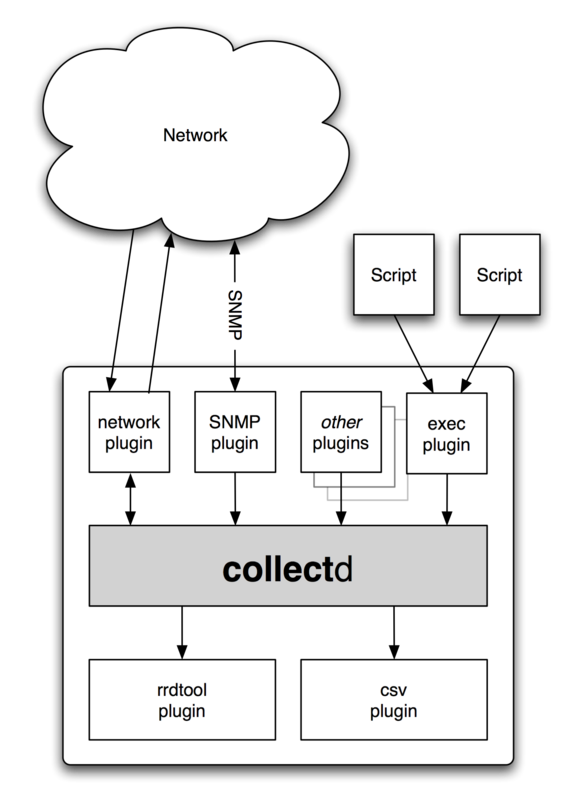
サーバーの状態をモニタするツールはいくつかありますが,今回は Collectd を使います.
Collectd はサーバのデータを手軽に収集することができるソフトです.プラグインアーキテクチャを採用しており,標準で様々なデータに対応した豊富なプラグインが用意されています.特に細かい設定をしなくても,プラグインを読み込んで基本的な設定をするだけで,欲しい情報を一通り収集してくれるのが特長です.
ただ,ディスクの使用量の収集に関しては 1 つ問題があります.具体的には,標準で付属する DF plugin はマウントポイント毎に使用量を取得するため,ZFS のサブボリュームを使っていると意図した値が取得できません.
ZFS 用のプラグイン(Plugin:ZFS ARC)も用意されているのですが,出力対象が ARC (Adaptive Replacement Cache) のステータスを対象にしており,ディスクの使用容量の取得には使えません.
そこで,ZFS のボリューム使用量を取得するプラグインを作成してみました.
プラグイン
作成したのはこちら.実行権限をつけた上で /usr/lib/collectd/zpool_df.py に保存します.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
#!/usr/bin/python # -*- coding: utf-8 -*- # collectd Plugin:Zpool_DF # plugin for zpool to collect free space and usage. import os, sys, time import subprocess as sp import pprint PLUGIN_NAME = 'zpool_df' def get_zpool_list(): child = sp.Popen(['zpool', 'list'], stdout=sp.PIPE) child.wait() if child.returncode != 0: sys.stderr.write('Failed to get zpool list.') sys.exit(2) zpool_list = [] zpool_lines = child.stdout.read().splitlines() zpool_lines.pop(0) for line in zpool_lines: zpool_list.append(line.split()[0]) return zpool_list def get_zpool_usage_info(zpool): child = sp.Popen(['zpool', 'get', '-pH', 'size,allocated,free', zpool], stdout=sp.PIPE) child.wait() if child.returncode != 0: sys.stderr.write('Failed to get zpool info.') sys.exit(2) info_list = child.stdout.read().splitlines() usage_info = {} for line in info_list: param = line.split() usage_info[param[1]] = int(param[2]) return usage_info def get_zpool_info_map(): info_map = {} for pool_name in get_zpool_list(): info_map[pool_name] = get_zpool_usage_info(pool_name) return info_map ############################################################ hostname = os.getenv('COLLECTD_HOSTNAME') or os.popen('hostname').read().rstrip() interval = (os.getenv('COLLECTD_INTERVAL') and float(os.getenv('COLLECTD_INTERVAL'))) or 30 while True: for name, info in get_zpool_info_map().items(): for item, value in info.items(): print 'PUTVAL %s/%s/%s-%s-%s interval=%s N:%d' % ( hostname, PLUGIN_NAME, 'gauge', name, item, interval, value ) sys.stdout.flush() time.sleep(interval) |
パーミッション設定
zpool による情報取得を root 以外にも行えるように /dev/zfs のパーミッションを変更します.
|
1 2 |
# sudo chmod 660 /dev/zfs # sudo chown root:sudo /dev/zfs |
これによって, sudo グループに入っているユーザも zpool コマンドを実行できるようになります.
動作確認
プラグインを実行して,下記のような出力が得られれば OK です.CTRL-C で終了させます.
|
1 2 3 4 |
$ /usr/lib/collectd/zpool_df.py PUTVAL ethiopia/zpool_df/gauge-storage-allocated interval=30 N:2989808230400 PUTVAL ethiopia/zpool_df/gauge-storage-free interval=30 N:8967380721664 PUTVAL ethiopia/zpool_df/gauge-storage-size interval=30 N:11957188952064 |
collectd の設定
/etc/collectd/collectd.conf に以下を追加します.「kimata」の部分は,sudo グループの適当なユーザに変更してください.
|
1 2 3 4 5 |
LoadPlugin exec <plugin exec> Exec "kimata:sudo" "/usr/lib/collectd/zpool_df.py" </plugin> |
collectd を再起動すればデータの収集が始まります.
/var/log/syslog に変なログがでていなければ,準備完了です.
グラフ化
collectd のデータを Influxdb に突っ込んで,Grafana でグラフ化する場合,次のような設定を行います.
この例の場合,columbia というホストの storage という zpool の使用量をしています.
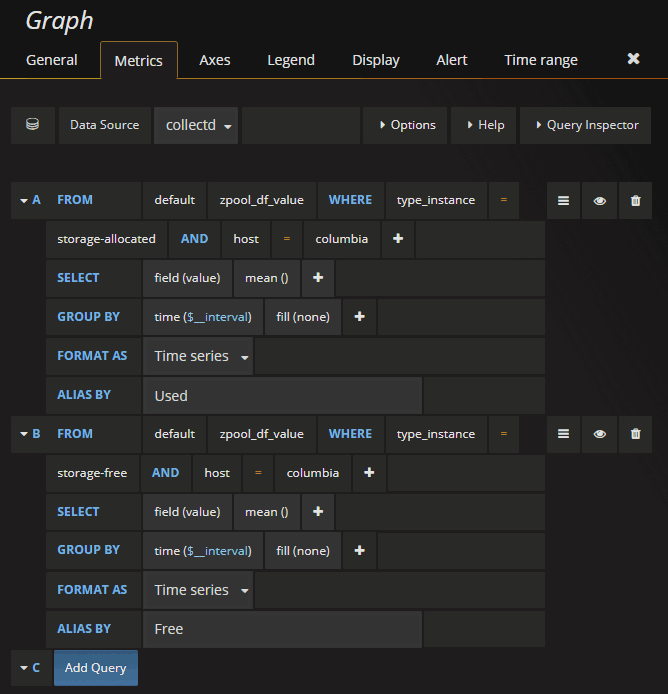
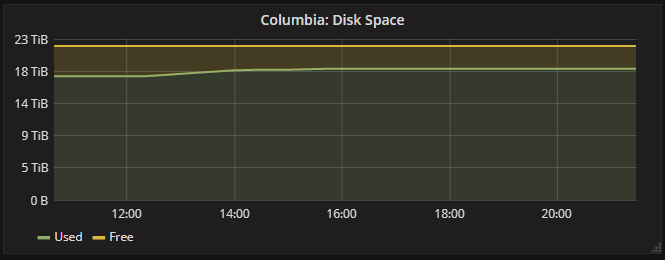
データが溜まってくると,次のようなグラフが表示されます.


コメント